- Buffer Pool(缓冲池)
- Change Buffer
- Adaptive Hash Index(一致性哈希索引)
- Log Buffer(日志缓冲)
Buffer Pool
Buffer Pool是InnoDB用来缓存数据表和索引的一块内存区域。Buffer Pool允许经常使用的数据可以从内存中被处理,从而加速数据的处理。在一些专用的服务器上,高达80%的物理内存被分配给buffer pool。
为了提升大容量数据读操作的效率,buffer pool被分成了多个数据页(Pages),数据页包含了多条数据。为了提升缓存管理的效率,InnoDB使用了数据页组成的链表作为实现。很少使用的数据会通过一种LRU算法的变体从缓存中被淘汰。
了解如何利用Buffer Pool,使得经常使用的数据保持在内存里,是MySQL调优的重要方面。
Buffer Pool LRU算法
通过一种”最近最少使用”(LRU)算法的变体,可以将Buffer Pool当作列表(list)管理起来。当需要空间将新的一个数据页增加到Buffer Pool时,最近最少使用的页面会被淘汰,并且新的数据页会被加入到列表的中间某位置。 这个中间点插入策略把列表分成了两个子列表:
- 在头部,最近被访问的”较新”的数据页的列表
- 在尾部,”不那么新”的数据页列表
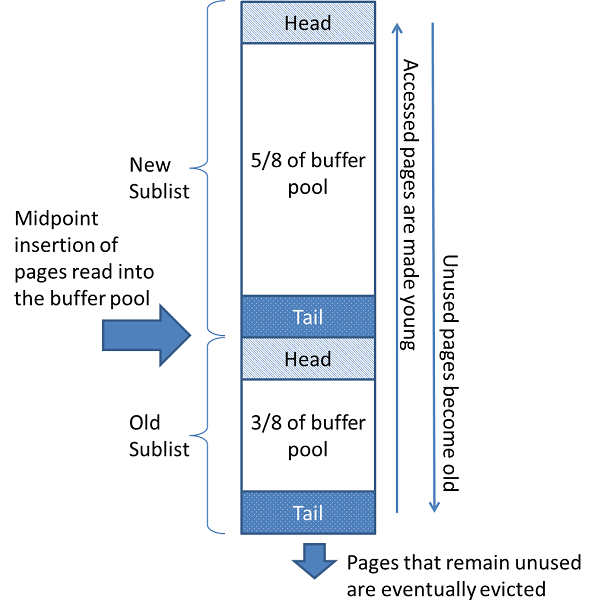
这个算法使得经常被使用的数据页保持在”新”子列表中。而”老”的子列表则包含了不那么经常使用的数据页;这些数据页是被淘汰的候选页。
默认地,算法执行如下:
- Buffer Pool的3/8被分配给”老”列表;
- 列表的中间点是”新”列表尾部和”老”列表头部的分界线;
- 当InnoDB读取一个数据页到内存时,默认把它插入到中间点位置(”老”列表的头部)。一个数据页之所以被读取,是因为有诸如SQL查询等用户发起的操作需要,或者是被作为由InnoDB自动发起的”预读”的一部分;
- 访问一个”老”列表中的数据页会使它变得”年轻”,从而移动到”新”列表的头部;(需要额外注意的是)如果这个数据页被读取是因为用户发起的操作,那么”首次访问”(first access)将会立即发生,并且数据页进入”新”列表;如果这个数据页被读取是因为”预读”,那么”首次访问”(first access)不会立即发生,甚至在该数据页淘汰之前都不会发生。
- 当数据库运行时,缓冲池中未被访问的页通过向列表的尾部移动来“老化”。”新”子列表和”老”子列表中的数据页都会随着其他页面变为新页面而老化。”老”子列表中的页面还会其他数据页插入到中间点而老化。逐渐的,一直未被使用的数据页到达”老”子列表的尾部并且被淘汰。
默认地,通过查询而被读取数据页会被立即移动到”新”子列表,这意味着它们可以在Buffer Pool中呆的更久。举例来说,为mysqldump操作执行表扫描,或者一个没有where条件的select语句,会将大量数据带入Buffer Pool,并且淘汰等量的旧数据,尽管新数据再也不会被使用。同样,由”预读”后台线程
加载且仅访问一次的数据页将移动到”新”列表的头部。这些场景会将频繁使用的数据页推到”老”子列表而逐渐被淘汰。
InnoDB标准监控器输出的”BUFFER POOL AND MEMORY”部分,包含了几个关于Buffer Pool LRU算法操作的字段。
Buffer Pool配置
你可以配置Buffer Pool的各个方面来提高性能。
- 理想情况下,在给服务器上的其他进程留下足够的内存来(保证其)不过度分页(避免使用Swap)地运行的情况下 ,你(应该)将Buffer Pool的大小设置为尽可能大的一个值。Buffer Pool越大,InnoDB越表现的像一个内存数据库。
- 在具有足够内存的64位系统上,您可以将缓冲池拆分为多个部分,以最大限度地减少并发操作之间对内存结构的竞争。
- 您可以将频繁访问的数据保留在内存中,而不考虑【将大量不经常访问的数据引入Buffer Pool的操作】导致突然活动高峰。
- 您可以控制执行预读请求的方式和时机,以便在预期很快需要页面的情况下将页面异步预取到缓冲池中。